Flat한 데이터 → Hierarchy UI로 보여주기
2023.11.10
목차
• 서문
• 어디에서 해야할까?
• 어떻게 해야할까?
• 끝맺음
서문
hierarchy, 사전적 의미로 계층을 뜻합니다. 계층이란 시스템이 상위와 하위 요소로 구성되어 있는 방식을 말합니다. 이는 종종 부모-자식 관계로 설명되며, 상위 요소는 부모로, 하위 요소는 자식으로 간주됩니다. 각 요소는 자신보다 하위 레벨에 있는 여러 요소를 가질 수 있지만, 자신보다 상위 레벨의 단 하나의 요소에만 속합니다.
flat한 구조는 간단하지만 복잡한 관계를 화면에 나타날 때에는 한계가 있습니다. 반면에 hierarchy 구조는 복잡한 관계와 중첩된 정보를 효과적으로 표현할 수 있습니다. 화면에 hierarchy 구조로 보여줘야 하는 상황에서 항상 우리가 원하는 형태로 데이터가 제공되지 않습니다. 떄떄로 flat한 구조의 데이터를 hierarchy 구조로 변환해야 하는 상황에 직면하게 됩니다.
어디에서 해야할까?
이제 이 flat 구조를 hierarchy 구조로 변환하고 hierarchy 구조를 flat 구조로 변환하는 작업을 해야 합니다. 그렇다면 어디에서 하는 것이 적합할까요? 이러한 결정에는 일반적인 규칙이나 항상 옳은 선택이 없는 것 같습니다. 현재 상황에서 가장 효율적인 방법으로 결정해야 하는 것입니다.
저희는 이 작업을 프론트엔드 진영에서 진행하기로 결정했습니다. 이유는 만약 이 작업을 백엔드에서 진행하게 된다면 너무나 많은 작업들이 백엔드에서 이루어지기 때문입니다. 현재 사용하고 있는 관계형 데이터베이스에 hierarchy 구조의 데이터를 저장하는 것이 불가능한 것은 아니지만 복잡성이 쉽게 늘어난다고 알고 있습니다.
또한 요구사항이 변경되어 hierarchy 구조에 변경이 생김으로 인해 API가 변경되는 것보다는 프론트엔드에서 flat한 구조의 데이터를 hierarchy 구조로 변경하는 로직을 수정하는 것이 공수비용이 더 적다고 생각했습니다.
어떻게 해야할까?
먼저 구현해야 하는 UI를 보겠습니다.
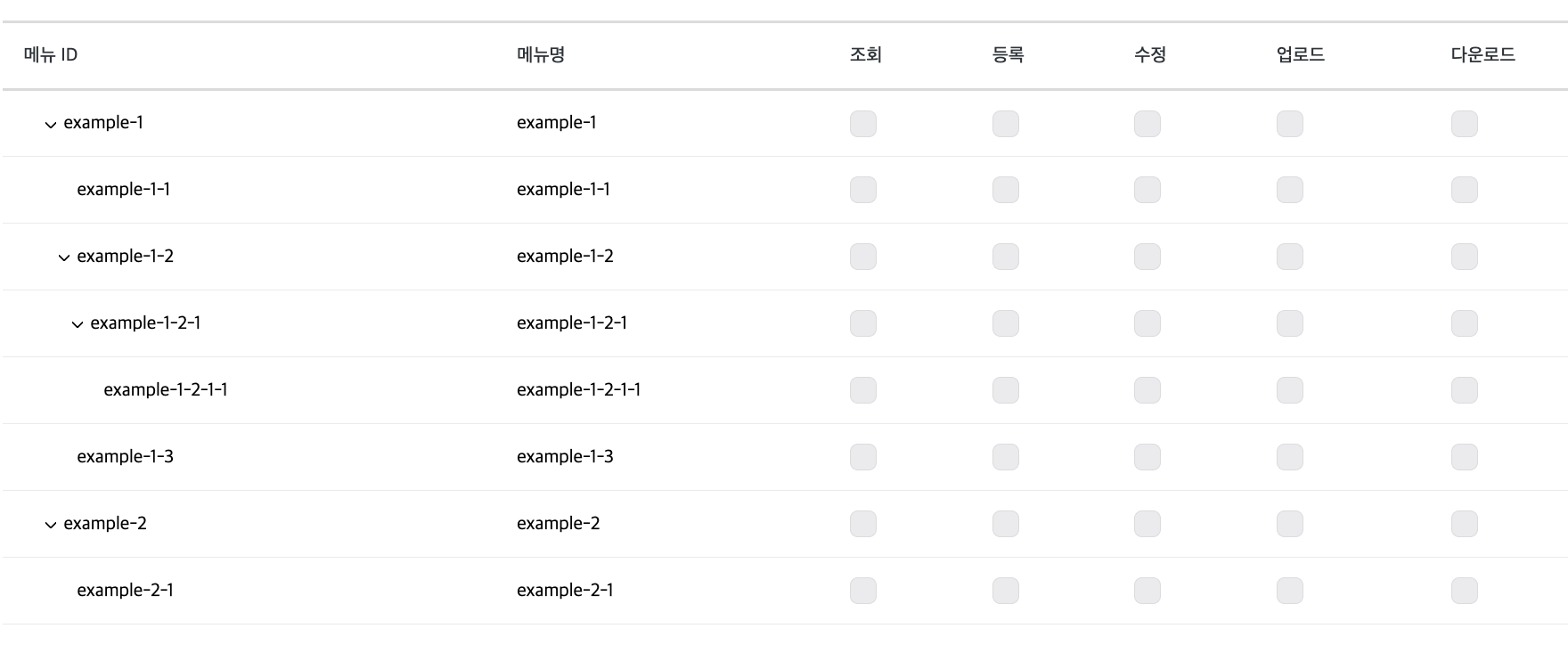
• 자식 계층으로 내려갈수록 계층 UI는 오른쪽으로 이동함으로써 자식 계층이라는 것을 명시적으로 보여줘야 합니다.
• 부모 계층에서 Arrow 모양의 버튼을 통해 접는다면 자식 계층 모두 화면에서 보이지 않아야 합니다.
이 두가지 UI 특징이 존재하는 것을 인지하고 구현을 해봅시다. 그리고 앞으로는 하나의 계층을 row 라고 지칭하겠습니다.
일단 백엔드에서 제공하는 API 명세를 확인해보겠습니다. flat한 구조에서 hierarchy 구조로 바꾸기 위한, 즉 부모-자식 관계를 저장하고 있는 데이터는 menuId 와 upMenuId 입니다. upMenuId 는 부모 row의 menuId 값과 동일합니다. 그리고 최상위 row, 현재 화면에서 메뉴 ID가 example-1과 example-2 의 부모 row는 존재하지 않기에 해당 row의 upMenuId 값은 null 입니다.
depth 는 계층의 단계를 지칭합니다. 최상위 row의 depth 값은 1이고 자식 row의 depth 값은 2입니다. seq 는 같은 계층의 순서를 의미합니다. example-1-2 는 전체 row들에서는 3번째이지만 depth가 1인 계층에서는 seq의 값은 2입니다.
{
flatDatas: [
{
menuId: 1,
upMenuId: null,
menuName: "example-1",
menuCode: "example-1",
depth: 1,
seq: 1,
// ...more data
},
{
menuId: 2,
upMenuId: 1,
menuName: "example-1-1",
menuCode: "example-1-1",
depth: 2,
seq: 1,
},
{
menuId: 3,
upmenuId: 1,
upMenuId: "example-1-2",
menuCode: "example-1-2",
depth: 2,
seq: 2,
},
{
menuId: 4,
upmenuId: 3,
upMenuId: "example-1-2-1",
menuCode: "example-1-2-1",
depth: 3,
seq: 1,
},
{
menuId: 5,
upmenuId: 4,
upMenuId: "example-1-2-1-1",
menuCode: "example-1-2-1-1",
depth: 4,
seq: 1,
},
{
menuId: 8,
upmenuId: 1,
upMenuId: "example-1-3",
menuCode: "example-1-3",
depth: 2,
seq: 3,
},
{
menuId: 6,
upmenuId: null,
upMenuId: "example-2",
menuCode: "example-2",
depth: 1,
seq: 1,
},
{
menuId: 7,
upmenuId: 6,
upMenuId: "example-2-1",
menuCode: "example-2-1",
depth: 2,
seq: 1,
},
];
}
예상 구현 형태입니다.
const HierachyTable = ({datas}) => {
// ...구현해야하는 코드들
return <TablePreset tableData={datas} tableConfig={tableConfig} />;
};
위 코드에서 보이는 TablePreset 컴포넌트는 디자인 패키지 안에 Table 형태를 나타내는 컴포넌트입니다. 그리고 tableData props는 보여줄 data를 넣어주는 부분입니다. tableConfig props는 메뉴(메뉴 ID, 메뉴명 등등)을 지정할 수 있는 값을 넣을 수 있습니다.
const tableConfig = [
{
name: "menuCode",
thText: "메뉴 ID",
},
{
name: "menuName",
thText: "메뉴명",
},
{
name: "readYn",
thText: "조회",
valueCallback: (data) => renderCheckboxField(data, "readYn"),
},
{
name: "writeYn",
thText: "등록",
valueCallback: (data) => renderCheckboxField(data, "writeYn"),
},
{
name: "updateYn",
thText: "수정",
valueCallback: (data) => renderCheckboxField(data, "updateYn"),
},
{
name: "uploadYn",
thText: "업로드",
valueCallback: (data) => renderCheckboxField(data, "uploadYn"),
},
{
name: "downloadYn",
thText: "다운로드",
valueCallback: (data) => renderCheckboxField(data, "downloadYn"),
},
];
HierachyTable 은 디자인 패키지에 위치해 있는 컴포넌트입니다. 그래서 범용성을 고려해야 합니다. HierachyTable 컴포넌트가 API field에 종속되면 범용성이 떨어질 수 밖에 없는데요. 그래서 외부에서 matchKey 값을 전달받아 hierarchy 구조를 구성하는데 반드시 필요한 rowId , upRowId , seq , depth 값을 API field 와 HierachyTable 내부 로직에서 필요한 값에 mapping 시킵니다. 이 덕분에 field의 key naming이 menuAuthId , id 등등 어떠한 것이더라도 mapping만 올바르게 시켜준다면 API field naming에 종속되지 않고 범용성 있게 사용할 수 있습니다.
const matchKey = {
_rowId: "menuAuthId",
_upRowId: "upMenuAuthId",
_seq: "seq",
_depth: "depth",
};
const HierachyTable = ({matchKey, datas}) => {
// ...구현해야하는 코드들
return <TablePreset tableData={datas} tableConfig={tableConfig} />;
};
첫 번째로 response로 내려오는 데이터를 순서에 맞게 정렬를 해야합니다. 물론 row들이 순서에 맞게 내려오는 것이 happy case 이지만 그렇지 못하기 때문에 필요합니다. 정렬를 하기 위한 data는 _rowId , _upRowId , _seq 입니다. 정렬하기 위한 조건들이 존재합니다.
• A라는 row의_rowId 가 B라는 row의 _upRowId 와 같다면 B row는 A row 뒤로 정렬해야 합니다.
• _seq 의 값이 작을수록 앞으로 정렬해야 합니다.
• row의 _upRowId 가 null 이라면 최상위 row를 의미합니다.
const sequenceSort = (rows: []) => {
const result = [];
const mostUpperRows = rows
.filter((row) => isNullOrUndefined(row._upRowId))
.sort((a, b) => a._seq - b._seq);
const lowerRows = rows.filter((row) => row._upRowId !== null);
const dfs = (id: number, rows: []) => {
const currentIdRows = lowerRows
.filter((row) => row._upRowId === id)
.sort((a, b) => a._seq - b._seq);
if (currentIdRows.length === 0) {
return;
} else if (currentIdRows.length > 0) {
for (const row of currentIdRows) {
rows.push(row);
bfs(row._rowId, rows);
}
}
};
let nullPointer = 0;
while (nullPointer < mostUpperRows.length) {
const id = mostUpperRows[nullPointer]._rowId;
const rows: T[] = [];
dfs(id, rows);
result.push(mostUpperRows[nullPointer]);
result.push(...rows);
nullPointer++;
}
return result;
};
먼저 최상단 row(_upRowId 가 null인 row)와 아닌 row(_upRowId 가 number인 row)를 분리해서 _seq 값이 작은 순으로 정렬합니다. 그 후 dfs, 깊이 우선 탐색을 통해 노드들을 탐색해야 합니다. 왜냐하면 hierarchy 구조는 마치 다중 트리 구조와 흡사하기 때문입니다.
const HierachyTable = ({matchKey, datas}) => {
useEffect(() => {
const {_seq, _rowId, _depth, _upRowId} = matchKey;
if (!datas) return;
const rows = datas.map((data) => {
return {
...data,
_seq: data[_seq],
_rowId: data[_rowId],
_depth: data[_depth],
_upRowId: data[_upRowId],
};
});
sequenceSort(rows);
}, []);
return <TablePreset tableData={datas} tableConfig={tableConfig} />;
};
위 정렬은 Table이 만들어지는 처음 한번만 실행이 필요하기에 useEffect , Dependency가 [] 인 곳에 위치하였습니다.
두 번째로 flat한 구조를 hierarchy 구조로 만들어야합니다.
const flatToHierachySort = (rows: []) => {
const rowIdMap = new Map();
rows.forEach((row) => {
rowIdMap.set(row._rowId, row);
if (row._upRowId !== null) {
const parentRow = rowIdMap.get(row._upRowId);
if (parentRow) {
parentRow._children.push(row);
}
}
});
return rows;
};
먼저 Map 자료구조를 만든 후 row의 _upRowId 를 rowIdMap 에서 조회해서 _children 라는 배열 타입의 property에 추가합니다.
const HierachyTable = ({matchKey, datas}) => {
const [initData, setInitData] = useState([]);
const [showData, setShowData] = useState([]);
useEffect(() => {
const {_seq, _rowId, _depth, _upRowId} = matchKey;
if (!datas) return;
const rows = datas.map((data) => {
return {
...data,
_children: [],
_seq: data[_seq],
_rowId: data[_rowId],
_depth: data[_depth],
_upRowId: data[_upRowId],
};
});
const res = flatToHierachySort(sequenceSort(rows));
setInitData(res);
setShowData(res);
}, []);
return <TablePreset tableData={showData} tableConfig={tableConfig} />;
};
이제 구현해야하는 hierarchy 구조까지는 화면에 보여줄 수 있게 되었습니다.
세 번째로 이제 hierarchy 구조를 접고 펼칠 수 있는 기능을 구현하기 위해 이 fold 상태인 row의 id를 상태로 가지고 있어야 합니다. fold 상태인 row들의 id를 상태로 가지고 있어서 제어할 수 있지만 해당 row의 자식 row들을 제어할 수 없다는 점이 있습니다.
const filterFoldRowChildren = <T,>(rows: [], foldRowsId: number[]) => {
const ids = new Set(foldRowsId);
return rows.filter((row) => {
if (row._upRowId === null) {
return row;
}
if (ids.has(row._upRowId)) {
if (row._children.length > 0) {
ids.add(row._rowId);
}
return;
}
return row;
});
};
그래서 fold 상태의 row id를 두가지로 분리하였습니다. 외부 데이터(foldRowsId)와 함수 내부 데이터(ids)입니다. 이로 인해 외부 데이터로부터 발생하는 사이드 이펙트(부모 row가 접히면 자식 row들도 보이지 않아야 하는 점)를 함수에 위임함으로 외부 데이터(state)를 최소화하려고 하였습니다.
const HierachyTable = ({matchKey, datas}) => {
const [foldRowsId, setFoldRowsID] = useState([]);
const [initData, setInitData] = useState([]);
const [showData, setShowData] = useState([]);
useEffect(() => {
if (foldRowsId.length === 0 && initData.length === 0) return;
const res = initData.map((row) =>
foldRowsId.includes(row.menuAuthId)
? {...row, _isFold: true}
: {...row, _isFold: false}
);
setShowData(filterFoldRowChildren(res, foldRowsId));
}, [foldRowsId]);
return <TablePreset tableData={showData} tableConfig={tableConfig} />;
};
위 정렬은 fold가 발생할 때마다 실행이 필요하기에 useEffect , Dependency가 [foldRowsId] 인 곳에 위치하였습니다.
이제 row들을 접고 펼칠 수 있는 기능을 구현할 수 있게 되었습니다.
끝맺음
위 컴포넌트를 구현하면서 크게 2가지를 주안점으로 두고 구현하였습니다.
1 외부 데이터(Remote data)에 최소한으로 의존하기
2 디자인 패키지에 속한만큼 범용성있게 구현하기
그러다보니 구현을 위한 데이터 중 외부에서 주입해줘야 하는 데이터와 내부에 존재하는 데이터를 나누는 기준이 중요하다는 생각이 들었습니다. 내부에 존재하는 데이터의 비중이 크다면 범용성이 떨어질 가능성이 높아집니다. 반면 외부에서 주입해줘야 하는 데이터의 비중이 크다면 사용하는 측에서 불편함을 느낄 가능성이 높습니다. 이번에 HierachyTable 컴포넌트를 구현하면서 이 둘의 적정선을 고민하면서 개발하는 좋은 기회가 되었습니다.